

How Durable is Our Visibility into AI Cyberattacks?
As AI gets better at hacking, sources of threat intelligence on its capabilities and use may deteriorate

How useful are AI systems for attackers? How wide is their adoption? What attack strategies do they enable? Anyone trying to mitigate AI-driven cyberthreats needs up-to-date answers to these questions. But currently, our view of AI’s cyber capabilities and their adoption by attackers is remarkably murky.
Today this picture is drawn from a thin set of sources: two almost saturated cyber ranges1, occasional incident reports published by threat intelligence firms, and AI companies reporting the number of vulnerabilities their newest model found. However, even these sources of threat intelligence could be fragile in the next years. Maintaining visibility into AI cyber threats is a crucial basis for sound policymaking and enables security practitioners to adapt to emerging AI threats in time.
Four questions:
What sources of threat intelligence on AI cyber capabilities and real-world usage can observers draw on?
How informative are these data sources?
Will they persist if AI cybercapabilities continue to rise?
Who has control over the data?
I find that sources of threat intelligence - especially those revealing how sophisticated attackers use AI in cyberattacks - are at risk of diminishing as attackers stop using API-hosted LLMs and share less information on public channels, and LLMs become stronger at maintaining operational security. Additionally, some sources are only held by commercial actors who might not share their insights.
Sources of Threat Intelligence
Defenders have access to six sources from which they can gauge AI capabilities and usage:
Cybercapability evaluations: Controlled tests measuring how well models perform offensive cyber tasks.
Real-world vulnerability discovery and pen-testing: The success of AI tools in dual-use defensive tasks indicates how capable AI is at cyber offense.
Open-source AI pen-testing tools: Publicly available offensive tools reveal how AI is used and indicate attackers’ capabilities.
Underground ecosystem monitoring: Forums and marketplaces where attackers trade AI tools and debate their use.
Incident forensics: Post-attack analysis of malware and logs to work out whether and how AI was involved.
LLM API usage data: Provider logs revealing exactly how attackers use API-hosted models.
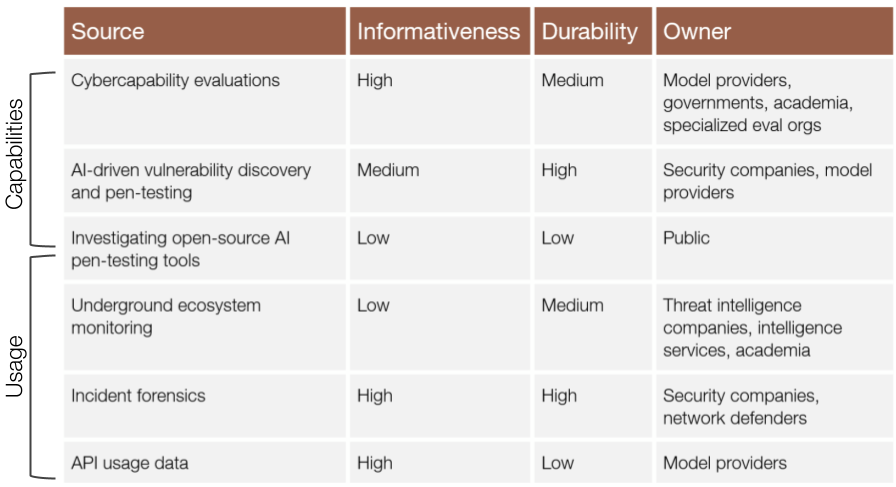
Table: My judgment of how important each threat intelligence source is for informing defenders and how likely it is to persist over the next years
Cybercapability evaluations
To assess AI cybercapabilities, observers turn to evaluations. Over the past 2 years, these tests have developed from answering multiple-choice questions about cybersecurity to solving capture-the-flag challenges to running autonomous long-run attacks in cyber-ranges. These evaluations provide clear quantitative measures over time on the capability of AIs at various cyberoffensive tasks. While many evaluation results are made public, governments, model providers, or evaluation organizations might decide not to share their findings.
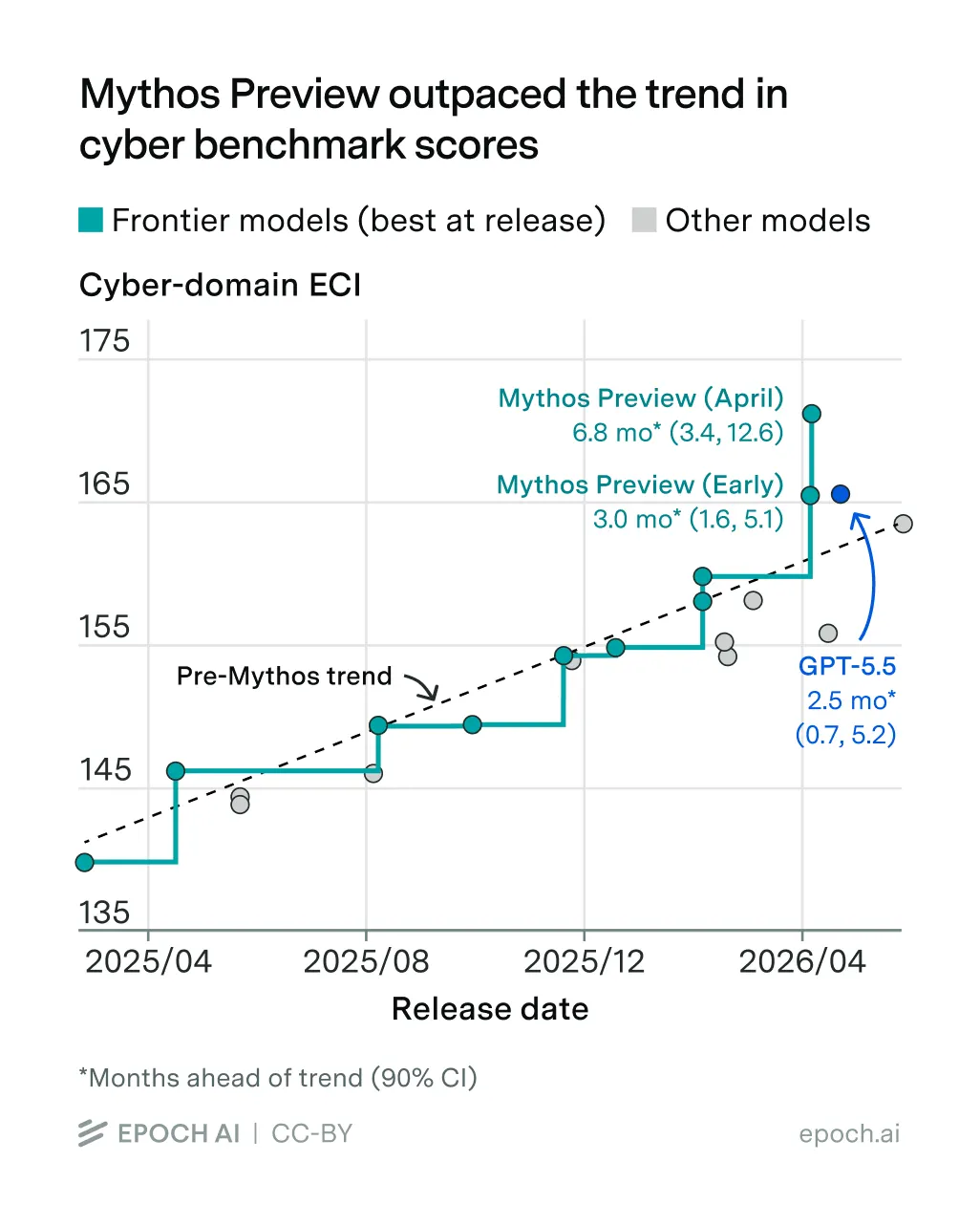
Aggregated cyberbenchmark scores of models over time.
Taken from EpochAI Gradient Update: Are Mythos’ cyber capabilities overhyped?
Developers of evaluations are struggling to build more difficult tests quickly enough to keep pace with increasing cybercapabilities. Even the most challenging evaluations are quickly saturated upon release. New approaches might keep pace, but evaluations may stop producing useful insights once AI cybercapabilities outgrow humans’ ability to test them. They also face an eval-to-real gap: real attacks use different tools, operate in more complex environments, and face live defenders.
Real-world AI vulnerability discovery and pen-testing
Defenders are increasingly using AI-enabled tools to find weaknesses in real systems. Finding novel vulnerabilities and penetrating networks are dual-use tasks. If defenders find that models are highly capable at defensive tasks, then models likely offer substantial uplift to attackers. For example, when Anthropic announced that Mythos found hundreds of vulnerabilities across highly defended codebases, many observers were alerted to the possibility of attackers using these capabilities. While such vulnerability discovery uses AIs to scan codebases in order to identify previously unknown vulnerabilities, agentic pen-testing tools use AI to exploit known weaknesses to compromise a system. Such agentic pen-testing tools can even outperform humans. For example, the web-pentesting agent XBOW ranked 1st place on a bug-bounty platform.
Cybersecurity companies, AI companies and network defenders will keep measuring AI’s ability to find weaknesses and compromise codebases. However, the information they publish is heavily restricted and shaped by commercial interests, so it is difficult to interpret with confidence. After Anthropic announced the vulnerability discoveries made by Mythos, observers debated the ulterior motives behind Anthropic’s communication, the significance of the vulnerabilities, and the ability of smaller models to find them. Additionally, defensive usage is not a perfect mirror of offensive tasks: attackers use different tools than defenders, and AI-pentesting tools are often run within a narrow scope or time window, without active defenses.
Open-source AI pen-testing tools
Open-source AI tools for pen-testing - such as PentestGPT, HexStrike-AI, or CyberStrikeAI - are used by cybercriminals in real attacks. Anybody can study these tools to uncover the attack strategies and techniques AI enables. They can also evaluate the effectiveness of these tools to indicate what capabilities attackers have access to.
However, sophisticated attackers likely have access to stronger or specialized tools that are not publicly available. Thus, testing can at most provide a floor. Tooling could become less important when more capable AI systems can write their scaffolding. Further, it is unclear whether actors will continue to release such tools openly: security researchers might be worried about the dual-use nature of these tools2 and cybercriminals might want to sell them instead of giving them away freely.
Underground ecosystem monitoring
On underground forums, attackers acquire AI-enabled cybertools and discuss tactics about their AI use. For example, Google’s Threat Intelligence Group (GTIG) has found criminals selling jailbroken models and a marketplace for AI-based offensive tools. This monitoring reveals the demands and willingness to pay of cybercriminals, the tools available to them, and the diffusion of cyberoffensive AI tools. Cybercriminals also share opinions and tips on using AI for cybercrime in forums and chats. Dupont et al collected and analyzed such conversations. They found that criminals actively debated which AI models to adopt and were generally skeptical of AI’s usefulness for cyberattacks.3
However, online discussions often contain uninformed opinions, and cybercriminals often sell low-quality tools for a quick profit. Ecosystem monitoring misses sophisticated attackers because they rarely share information or tooling via these channels. Going forward, threat actors might shift to private communication channels. And the information captured rarely discusses AI use in specific, attributable attacks.
Incident forensics
After an attack occurs, incident responders attempt to piece together how it happened and which techniques were used. Analyzing malware that was left behind can uncover AI use. The malware could contain indicators that attackers used coding agents to develop the attack, or it could make API calls to an LLM directly. For example, the LAMEHUG malware - discovered by GTIG - queries LLMs during an attack to generate new code on the fly. Defenders can also investigate system logs that might reveal behavioral indicators of AI involvement in an attack, such as inhumanly fast operating speed. In some cases, defenders even gain access to the attacker’s infrastructure and can see their AI usage in detail.4 Incident forensics can surface new types of AI use in cyberattacks and compile aggregate statistics on their prevalence. Such investigations can be supported by using AI agents to review large amounts of logs.
The main challenge lies in determining whether and how AI was involved in an attack solely from artifacts and behavioral logs. However, this could become more difficult as attackers are motivated to hide their attack strategies and as AIs’ ability to minimize revealing information about themselves during attacks grows. Attackers could spoof behavioral indicators defenders use to determine AIs, or use AI to improve their operational security and remain undetected during attacks.5 Additionally, only the affected party and possibly an incident response company have access to this data. Most cyberattacks are not made public6 or shared with other defenders, and many incidents are not even investigated deeply enough to determine AI involvement.
LLM API usage data
The clearest and most granular information about AI use in cyberattacks comes from the logs of model providers. By monitoring all API usage, these providers can see exactly what users asked the model to do and often gain substantial context on the attack. This approach allowed Anthropic to produce a database of AI-enabled tactics and techniques employed by cyberattackers and uncover the first large, nation-backed attack campaign using AI. By combining API logs with incident forensics, defenders can build a complete picture of an attack.7
However, this only catches attackers that use models via APIs and completely misses self-hosted open-weight models. Attackers may continue using APIs if closed models are clearly more capable, at least for some tasks. Yet attackers will likely move away from APIs8 if either (1) open-weight models are roughly comparable in cost-effectiveness to API-gated models9, (2) safeguards against cybermisuse become too restrictive to run attacks10, or (3) frontier capabilities are not needed to carry out most attacks successfully. Attackers can also split the attack across models from multiple providers, which leaves each with only an incomplete picture of the attack. Moreover, these data are held by model providers, who share findings only when it is in their interest to do so.
Outlook
Overall, sources of threat intelligence about AI use in real cyberattacks are fragile. Defenders may lose substantial visibility over the AI threat landscape in the next few years. While they will collect more data on AI attacks as these attacks become more common, cutting-edge attacks will become harder to detect. The key challenge lies in determining whether and how AI was used in an attack. This will become more difficult if AIs improve at maintaining operational security and avoid revealing information during attacks.
I am more optimistic about maintaining a rough overview of AI cybercapabilities. The biggest challenge here is to produce measurements that are both faithful to real attacks and provide precise, unambiguous assessments. Unfortunately, more realistic threat intelligence sources tend to provide less clear measurements. However, I believe new ways of assessing even more capable AI systems can be developed. It will be critical that this data is not distorted or held back by commercial interests.
Much threat intelligence lies with commercial actors. Data on defensive AI use, incident forensics, and API usage is concentrated among specific security companies, model providers, and commercial network defenders. By default, this data is not widely shared or is biased to commercial interests. This heavily reduces the value of the threat intelligence.
How can we retain visibility?
Governments should prioritize supporting the collection and sharing of unbiased threat intelligence on agent-based cyberattacks. This visibility is necessary for evidence-based decision-making about AI cyber risk and supports defenders in adapting to emerging threats. For example, if incident forensics and API monitoring indicate that a specific model has provided significant uplift in many cyberattacks, the government could mandate additional safeguards or access controls. And if evaluations and open-source demonstrations show that AI models are particularly effective at automating phishing attacks, network defenders can respond by scaling up employee training and refining email filters. To retain visibility, governments and philanthropic funders will need to fund research and build institutions that collect, combine, interpret, and share threat intelligence.
As API monitoring becomes less informative, funders (such as DARPA, IARPA, CISA, and philanthropic foundations) need to support research to strengthen AI-specific forensics. Security researchers should develop forensic tools to determine AI involvement in an attack from logs and artifacts. It will also be necessary to develop new methods for gathering agent-specific threat intelligence. For example, honeypots designed to attract and elicit information from agent-based attacks could prove to be a durable source of granular data on the prevalence, goals, and tactics in AI cyberattacks.
Current cybercapability evaluations of LLMs saturate quickly and don’t indicate when we lose visibility over the AI threat landscape. AI researchers should invest in new evaluations that scale with increasing AI capabilities: pitting AI systems against each other as attackers and defenders, building active defenses into cyberranges, using AI to build ever more complex benchmarks, or testing them on real networks. Additionally, they should develop evaluations of LLMs’ capabilities to maintain stealth and operational security during cyberattacks.
By default, information on cyber capabilities and AI-related cyber incidents will be collected by the private sector. To ensure that unbiased information is reliably available to the public and policymakers, governments should build their own capacity to evaluate AI models on real-world cybertasks and collect first-hand threat intelligence from incidents. Since different actors see different slices of attacks, it is important to combine data sources. Governments should do this by founding an Agentic Cybersecurity Exchange akin to the Global Signal Exchange that operates in the public interest to aggregate and correlate threat signals about agentic cybersecurity risks from model providers, cloud platforms, and other agent infrastructure operators.
The best cybersecurity models solve all steps in these cyberranges on some of the tries. As of the release of Fable 5, UK AISI used a third unreleased cyberrange - “Doing Life” - that current models do not yet solve.
For example, the maker of HexStrike-AI withheld parts of the toolset for concern about empowering attackers. Source
This study covered discussions between January and July 2025, so findings are likely outdated now.
Gambit Security attained the Claude Code pre-prompt, permissions file, and project directory after accessing the attacker’s private servers. Check Point Research monitored the infrastructure used by an attacker during the development of VoidLink, which revealed internal documents and code that allowed them to reconstruct the AI usage and timeline of the malware development.
Rodriguez et al. (2025), in “A Framework for Evaluating Emerging Cyberattack Capabilities of AI,” find that LLMs can evade monitoring and defense systems. This capability is likely to improve alongside general AI cybercapabilities.
The DOJ found that only 15% of cybercrime is reported to law enforcement.
For example, Google Threat Intelligence Group cross-references API logs from Gemini with forensic data from real incidents (eg malware analysis) to see both sides of an attack.
Even if open-weight models are less capable, attackers could compensate by running smaller models for longer or building specialized scaffolds and thus achieve a similar cost-effectiveness to API-gated models.
For example, Anthropic released Claude Fable 5 with extremely restrictive guardrails that are likely to make it more difficult for cyberattackers to exploit it.
 | A guest post by
|