

Closing the AI Security Gap—Starting with Internal Models: Part I
After the ‘Mythos moment’, why the time to act is now and what frontier AI companies should be doing.

The security posture of frontier AI companies is not appropriately calibrated to the capabilities and safeguards of their most advanced—or otherwise dangerous—internally deployed models1. Poor security could allow malicious actors to exfiltrate or compromise model weights, algorithmic secrets, or other sensitive resources. It could also leave companies exposed to an internally deployed model itself becoming an insider threat—by seeking to exfiltrate itself from company systems, for example. As AI capabilities advance to the point where they can enable systemic national security risks, frontier AI companies and governments must urgently close the security gap.
To do this, we need to go further and faster on hardening the security controls around frontier AI while actively avoiding a race to the bottom on security standards. I argue that this should start—as a minimum—with internally deployed models because the most capable and potentially dangerous models likely operate ‘behind closed doors’. They include models without safety guardrails, models fine-tuned to maximize dangerous capabilities, models trained specifically to introduce or increase their ability or propensity to engage in dangerous or otherwise undesired behaviors, and models with access to internal training and deployment infrastructure. Internally deployed models are also the most opaque to the outside world, operating with little to no external scrutiny.
The urgency is sharpened by the UK government’s assessment that capabilities on benchmark tasks are now doubling at least every four months (versus eight previously) and is further underscored by the cybersecurity blunders at Anthropic over the past three months, which demonstrate a low baseline security posture. However, proposals for stronger AI security controls must be sensitive to the difficulty of the challenge and the incentives of frontier AI companies and their staff. This shouldn’t be an academic exercise in designing the most hardened architecture imaginable without regard to the organizations and individuals who would have to live with it. Proposals that ignore implementation costs will lead to further inertia. There is no current indication that the government will compel action, and there are powerful incentives in favor of little to no action beyond the status quo. Below, I lay out why hardening the security around frontier AI is needed now and what frontier AI companies should be doing about it. In Part II, I’ll turn to why and how governments must contribute to these efforts.
Why Improved AI Security is Needed Now
We must take seriously the near-term risk of an AI-related national security crisis based on recent evidence. As corroborated by the UK AI Security Institute, Anthropic’s Mythos Preview and OpenAI’s GPT-5.5 models demonstrate that autonomous offense-relevant cyber capabilities are advancing rapidly. Automated exploit generation is likely already compressing cyber-attacker timelines. The gap between vulnerability discovery and exploit confirmation has collapsed from 9.7 months in 2022—the year ChatGPT was released—to 10 hours today. The capabilities of these systems may now rival those of some of the most sophisticated and well-resourced cyber threat actors. In addition, a Mythos-like jump in biosecurity-relevant capabilities in the next six to twelve months is plausible, which could prove particularly destabilizing given that both threat detection and the development and deployment of defensive countermeasures take longer to scale.
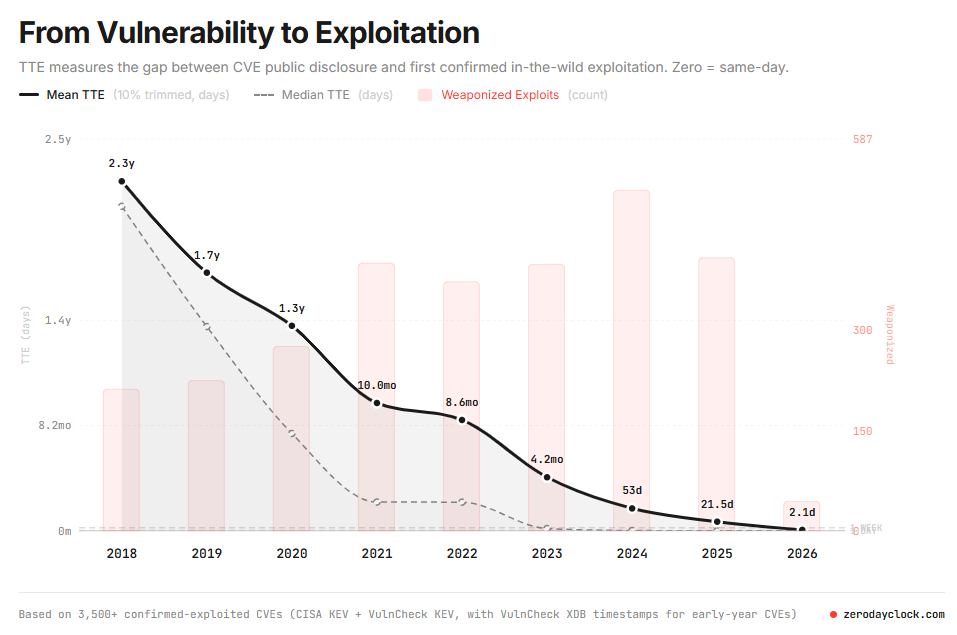
If models at these capability levels were obtained by malicious actors—through theft of model weights, for example—the consequences could be severe, potentially driving accelerated cyber offense or novel pandemics. Despite this, the security posture of frontier AI companies is broadly equivalent to RAND Security Level (SL) 3—a standard designed to disrupt cyberattacks from cybercrime syndicates and insider threats, but not from threat actors with greater resources and capabilities, such as nation-states2.
There have also been notable security lapses reported in frontier AI companies and this is not new. In 2023, a hacker reportedly compromised OpenAI’s internal messaging system and obtained private information about the company’s technology. However, the recent cluster of incidents at Anthropic is more concerning. Perhaps the most significant was the reported breach of Anthropic’s systems in April 2026. Access provided to a third-party contractor allowed an unauthorized group of users to reach the Mythos Preview model—on the same day the company launched its limited-release Project Glasswing program. Information about Mythos Preview itself reached the public domain earlier than Anthropic had intended as a result of a separate misconfiguration of the company’s Content Management System in March 2026. Later that month, source code for Anthropic’s Claude Code application was mistakenly exposed to the public.
What Frontier AI Companies Should Be Doing Now
Update Frontier AI Safety Policies to commit to a ‘differential security’ framework
At a minimum, frontier AI companies should jointly commit—via updates to their frontier AI safety policies—to harden their security posture in the short-term through a ‘differential AI security’ framework. This would identify internally deployed models that pose additional risk beyond the company’s leading publicly deployed frontier model and subject these to a stronger default security standard, based on the precautionary principle. It’s worth noting here that companies will consider the safeguards built in and the model—as well as its capabilities and propensities—when assessing risk. This security standard should:
Scale similarly to how Frontier AI Safety Policies assign security levels tied to the level of risk a model poses, but be expressly extended to internally deployed models;
Have a floor broadly equivalent to one that would successfully defend against RAND OC4 threat actors or higher, and
Be informed by technical expertise and other support—including financial—from the U.S. government (more to come in Part II).
In what appears to be an exception—rather than a common occurrence—in frontier AI safety policies, OpenAI’s Preparedness Framework (s. 4.4) accepts the principle that internally deployed models may require additional levels of security above what their publicly deployed frontier closed models might demand:
“Models that have reached or are forecasted to reach Critical capability in a Tracked Category [...] require additional safeguards (safety and security controls) during development, regardless of whether or when they are externally deployed.”
However, details on what additional security measures would be differentially applied to higher-risk internally deployed models—and how, on what timelines, and through what process—are either vague or missing entirely. This issue is not just limited to internally deployed models; there is also a general lack of specificity from frontier AI companies about what security measures for higher-risk models more broadly (i.e., above OpenAI’s High-capability threshold or equivalent).
It is also important to note that OpenAI would only apply additional safeguards to an internally deployed model in cases where the model in question has reached (or is forecasted to reach) a “Critical capability in a Tracked Category” and so would not necessarily cover all internally deployed models presenting additional risk compared to the company’s publicly deployed frontier model. This could happen for two reasons. First, some internally deployed models that might reach the Critical threshold may never be evaluated (more on this below). Second, some may pose a greater risk than models that have reached the High threshold but have not conclusively crossed into Critical territory.
Understand internally deployed model inventories and have a transparent process for systemically assessing their actual or potential risk
3 Not all internally deployed models necessarily require additional security measures. To identify those that may, however, companies need to have a comprehensive understanding of their internally deployed model inventories, including both solely-internal models and internal derivatives of publicly-deployed models. Anthropic’s February 2026 Risk Report (s. 7.9) is one example of this being done publicly.4 Frontier AI companies should inventory the following forms of internally deployed models:
Infrastructure models. Models that are developed specifically for internal workflows, with no expectation of being publicly released. These might include—for example—models used in AI R&D, automated anomaly monitoring, and monitoring other models for signs of dangerous or otherwise undesired propensities and actions.
Helpful-only models. Versions of models without model-level safeguards, often deployed for use in safety evaluations and research. Common among frontier AI companies for use by staff and in evaluation settings;
Model organisms. Models that have been trained specifically to introduce or increase their ability or propensity to engage in behaviors which—in usual deployment circumstances—would be considered dangerous. Examples include models that reward hack, fake alignment, exhibit emergent misalignment, or sandbag. These are designed to support safety-related research rather than to be used for malicious purposes.
Models that are more permissive and capable in dual-use applications. These are model derivatives designed to assist benign actors operating in dual-use fields by providing enhanced capabilities and more permissive safeguards. The most recent examples of this are GPT-5.4 Cyber and GPT-5.5 Cyber. GPT-5.4 Cyber, announced in April, is a derivative of GPT-5.4, which has been “purposely fine-tuned for additional cyber capabilities and with fewer capability restrictions.” GPT-5.5 Cyber—which was announced just three weeks after GPT-5.4 Cyber and is currently an initial preview version—is a derivative of GPT-5.5, which is “primarily trained to be more permissive on security-related tasks”. However, unlike GPT-5.4 Cyber, GPT-5.5 Cyber “is not intended to significantly increase cyber capability beyond GPT‑5.5.” These models are being made available to vetted cyber defenders through OpenAI’s Trusted Access for Cyber program.
This category would also include maliciously fine-tuned models. These are versions of models with additional post-training on datasets relevant to dual-use capabilities (e.g., biological data). These are used to understand the ceiling of capabilities that could be elicited from a model after release, informing safety research and deployment decisions. They are particularly relevant when the standard version of the model may be distributed openly.
There may be cases where internally deployed models never undergo evaluation to determine whether they have reached a capability threshold—or another indicator of concern—that would necessitate applying higher security standards. This could happen with derivatives of publicly deployed models that are not themselves intended for public release—such as those used for safety R&D purposes in a small deployment within the company.
Therefore, frontier AI companies—in addition to having a fine-grained understanding of their model inventory—should have an automated process that triages all internally deployed models. The triage process should establish whether the model in question should undergo a comprehensive set of evaluations to understand and stress-test its capabilities, safeguards, and propensities, underpinned by a risk assessment. The risk assessment should, as a minimum, consider the following—regardless of the internally deployed model’s origin or intended deployment path:
Relevant information about the model (e.g., what its capabilities are);
What access the model has to internal systems (e.g., training and deployment infrastructure);
Threat modeling based on:
What malicious actors might do with the model were it to be exfiltrated;
What impact could there be on the company or its end users if the model was compromised by a malicious actor, and;
What impact could there be on the company or its end-users if the derivative model became an insider threat, and
[If applicable] What the difference is between the derivative model and the base model (e.g., safeguards removed for capability elicitation research).
To conduct this triage and risk assessment, frontier AI companies may wish to use AI itself. However, if they do so, they should be alert to the risk of model collusion and take steps to mitigate it. It’s also important to note that models are not the only valuable assets within a frontier AI company. It may be prudent to extend the internally deployed model inventory to a broader ‘artifact inventory’—including training data and proprietary algorithms—and consider whether additional security measures should be applied to these, if appropriate.
Identify what security enhancements can be made now, commit to implementing them, and be transparent about progress
To drive further progress in hardening AI security controls, frontier AI companies should identify what security enhancements that would support a transition to an SL45 or higher posture can be made now6, commit to implementing them (and set a timeline for doing so), and provide regular updates on their progress toward this against transparent milestones. Understanding what security enhancements can be made should not be a one-off exercise but a dynamic, ongoing process—constantly updating as the capability and threat landscape evolves and new security solutions are developed—with implementation plans and timelines updated regularly to reflect these changes.
These efforts would not only help to surface what is currently possible but also what is not. These insights can then be used to enrich conversations with government agencies to help unlock progress in more challenging areas (more on this to come in Part II). The “Security” section of Anthropic’s Frontier Safety Roadmap is one example of where some of this is being done in the public domain, but it also lays bare the gap between the company’s current security posture and where it aims to be within roughly the next year.
Understand tradeoffs associated with hardening AI security and make them more manageable
Hardening AI security controls should not be an academic pursuit aimed at defining the strongest security architecture one could ever implement with known science and engineering. These architectures must be designed with due regard to the people who will work under them, particularly the impact on their day-to-day working environment.
Companies should survey staff widely to understand what they want to see in a more secure workplace and how enhanced security protocols would influence the kinds of work they want to do and where they would do it. Once this is done—and on a regular basis going forward—companies should use the insights gleaned to implement enhanced security controls that have due regard to what staff need. This doesn’t mean paying lip service to the need for enhanced security. Rather, it is about tackling the issue proportionately, based on real evidence about staffers’ motivations and needs. Companies should also be thinking creatively about how additional sources of support—such as counseling, ethics advisors, and flexible working arrangements—can wrap around staff working in safety, security, and threat intelligence teams as they do their vital work under immense pressure.
Marshal capital toward R&D for AI security hardening
Frontier AI companies like OpenAI and Anthropic benefit from extremely high and growing valuations. OpenAI’s March 2026 funding round valued the company at $852bn post-money, while Anthropic was valued at $380bn post-money after its February 2026 funding round, with recent reporting suggesting the company is expected to complete another round this summer at a pre-money valuation of around $900bn. The capital raised in these funding rounds has been used primarily to fund increases in compute, but it has also placed significant financial resources in the hands of individuals and entities linked to the frontier AI companies. For example, the OpenAI Foundation—which holds a 26% equity stake7 in the for-profit OpenAI entity, with the potential for this to grow based on future valuation milestones—has committed to an initial $25bn of funding to philanthropic causes. In addition, recent reporting suggests that OpenAI allowed current and former staff to sell up to $30m worth of shares each last October—with 600 people taking up the offer, generating total proceeds of $6.6bn. Anthropic has also reportedly been allowing its staffers to sell some of their shares to investors.
Many people who work at frontier AI companies care deeply about the catastrophic risks AI could pose—whether through a model operating on its own volition or being harnessed by malicious actors. Their companies have signaled broader prosocial commitments—through structures like the OpenAI Foundation and the adoption by some of Public Benefit Corporation (PBC) status. This, together with public commentary from the leadership of frontier AI companies about the potential catastrophic risks associated with AI, makes it reasonable to expect that they would use their resources to help prevent such risks from materializing—and to strengthen societal resilience in case they do. Indeed, one of the OpenAI Foundation’s current programs—AI Resilience—is designed to do just that, even though current efforts do not appear to be focused primarily on mitigating catastrophic AI risks.
As such, frontier AI companies and those associated with them can help support greater hardening of AI security controls by investing in R&D to help bridge the gap between what is currently possible and what is not. Ideally, relevant and appropriate outputs from these efforts would then be open-sourced and shared widely across the ecosystem so that everyone can benefit. Examples include tools that support automated supply chain integrity verification, cybersecurity investigations, and AI model auditing. They could also be commercialized, perhaps with favorable terms for non-profit entities, small and medium enterprises, and government entities. There are already some steps in the right direction here. For example, Anthropic’s Frontier Safety Roadmap indicates that the company will seek to improve security practices across the industry through open-source contributions and other forms of sharing. PBC status provides legal cover for boards to take into account public benefit considerations and the interests of those affected by their companies’ activities. In principle, this creates space for investment in AI security R&D, even if doing so requires some balancing against shareholder interests. That said, if frontier AI PBCs like Anthropic and OpenAI proceed to IPO and beyond, their PBC models could come under more pressure from the increased attention that comes with being publicly listed. Therefore, PBC status should not be taken for granted or left unscrutinized.
Looking Forward
There is a widening gap between the capabilities of frontier AI systems and the security controls surrounding them. Closing the gap requires frontier AI companies to act now on several fronts: committing to a ‘differential AI security’ framework that applies stronger protections to higher-risk internally deployed models; building comprehensive inventories and automated triage processes to identify which models and artefacts warrant those protections; pursuing a transparent, dynamic transition toward SL4+ security measures; engaging staff as partners rather than subjects in that transition; and marshaling some of the extraordinary capital flowing through the ecosystem toward the R&D needed to make higher security standards technically viable.
Adopting a differential security framework would have the dual benefit of reducing the attack surface attached to higher-risk internally deployed models and allowing frontier AI companies to pilot a stronger company-wide security posture before implementing it more broadly. But there are limits to what voluntary corporate action can achieve on its own. More on that next time.
Aligned with our April 2026 paper on Risk Reporting for Developers’ Internal AI Model Use, internally deployed models refer to both unreleased models and internal deployments of publicly released models that feature enhanced capabilities, expanded access (e.g., integration with model training and deployment architecture), or reduced safety filters.
RAND Security Levels (SL) are defined as “the level of security a system requires to thwart increasingly capable operations”. SL3 represents a “system that can likely thwart cybercrime syndicates or insider threats.”
By actual or potential risk, I mean something like the following: actual risk is the risk the model poses with its existing safeguards, harness/scaffolding, training data, and access. Potential risk means the risk presented by the model if the existing safeguards, harness/scaffolding, training data, and access the model uses are changed from its original deployed version to elicit greater capabilities, permissiveness, and/or propensity to exhibit dangerous behaviors.
In the Anthropic case, rather than listing each model in use individually, they are allocated to categories corresponding to a model name. Therefore, it appears that derivatives of Claude Opus 4.6 are categorized under the ‘Claude Opus 4.6’ group, even if they are not the same version of Claude Opus 4.6 which is publicly deployed and there is no intention to deploy them publicly.
SL4 is defined as a “system that can likely thwart most standard operations by leading cyber-capable institutions,” and SL5 (the highest level in RAND’s framework) is defined as a “system that could plausibly be claimed to thwart most top-priority operations by the top cyber-capable institutions”.
Some security interventions that have been implemented by frontier AI companies are better aligned with SL4 requirements. By way of example, Anthropic’s February 2026 Risk Report (s.7.8.2) details the ‘binary allowlisting’ SL4 measure as part of the company’s security controls, as well as egress bandwidth controls, which, while enforced at a network-level rather than the hardware-level SL4 requires, represent progress toward it. There is some evidence to suggest that OpenAI may also be taking similar steps. However, there is less detail on this in the public domain.
Assuming the current size of the equity stake remains the same—and based on OpenAI’s last funding round—it is worth around $220bn.